知识点
- 学习流水线化的 Y86-64 处理器的设计和实现,深刻理解流水线冒险。
- 学习循环展开,理解其对程序性能的影响。
题目
Part A
要求
使用 Y86-64 指令集,编写关于 sum_list, rsum_list 和 copy_block 函数的 Y86-64 程序。
做法
参考书本图 4-7 即可,实现也较为简单。
Part B
要求
使用硬件控制语言(HCL)修改 sim/seq/seq-full.hcl,使得处理器支持 iaddq 指令。
做法
iaddq 指令将立即数和寄存器相加,并将结果写回寄存器。
具体参考 irmovq 指令的实现即可。
Part C
要求
在 ncopy.ys 中用 Y86-64 指令实现函数 ncopy:复制 src 到 dst,同时统计并返回其中正数的数量。
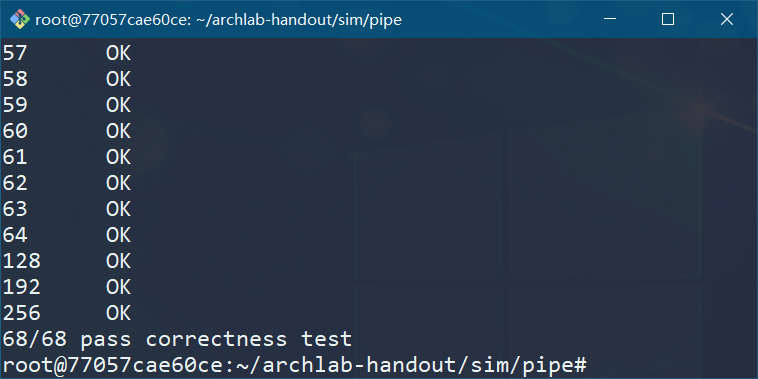
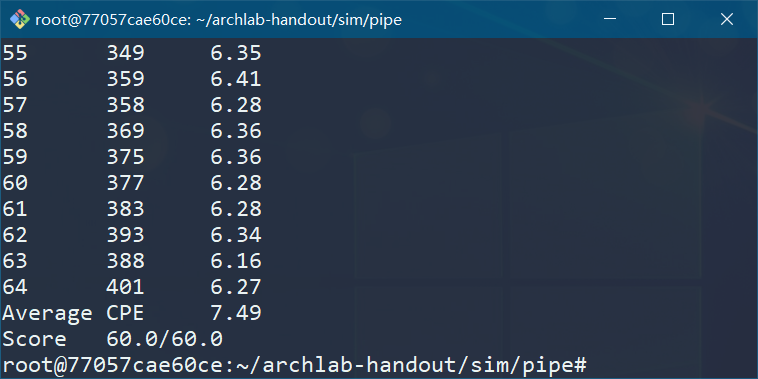
满分要求达到 CPE < 7.50。
1 | /* |
做法
首先实现最朴素的循环体:
1 | # %rdi = src, %rsi = dst, %rdx = len |
该实现使用 ./benchmark.pl 测试, CPE =
11.70。该实现需要经过优化来达到满分要求。
先简单介绍循环展开(Loop Unrolling),通过增加每次迭代计算的元素数量,从而减少循环的迭代次数:
减少循环不直接有助于计算的操作数量,比如循环索引。
不严谨地说,就是关键操作(比如乘法操作)数量不变,但是循环变量的加法减少了,这样就可以减少不必要的操作数量。
循环展开可以改变代码,有可能减少流水线冒险。
在朴素版本中,mrmovq (%rdi), %r10 和
rmmovq %r10, (%rsi) 存在数据相关:需要先将 *src
读取到寄存器 %r10 中,进而才能读取 %r10 值保存到
*dst。处理器通过暂停指令来处理该情况,参考下图情形:
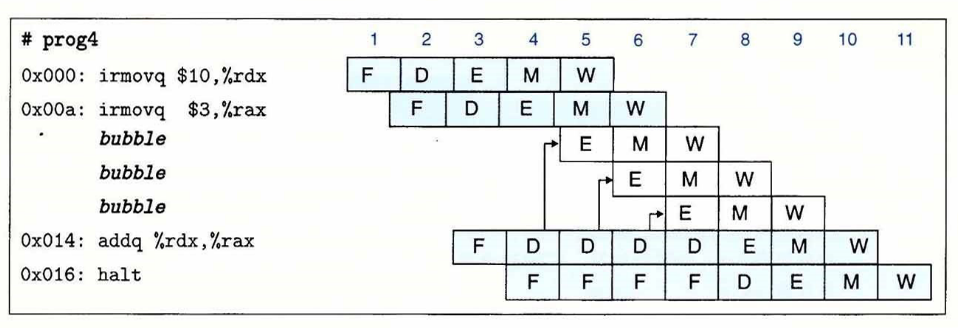
由于有转发机制,流水线处理器可以减少暂停的周期数,而不是图上的 3 个周期。
下面实现 2×1 循环展开:
1 | ncopy: |
该实现使用 ./benchmark.pl 测试, CPE = 8.87。
注意,此处将余数放到最后处理,可以去掉 %rdi, %rsi 和 %rdx 的加法操作,从而提高 CPE。
其中,将 iaddq $16, %rdi 置于
mrmovq 8(%rdi), %r9 和 rmmovq %r8, (%rsi)
之间,CPE 不会提升。此外,插入到 andq 和 jle
之间也不会提升 CPE。
因此,可得出结论 mrmovq 和 rmmovq
如果存在数据相关,只会暂停一个周期(即插入一个
bubble)。
进一步的优化考虑使用更多的寄存器来展开循环。因为 Y86-64 指令集仅支持 15 个寄存器,去掉已使用的寄存器和栈寄存器,剩余 10 个寄存器可用。所以最多能够编写 10×1 循环展开程序。
参考 2×1
展开,余数部分手动处理而不依赖循环结构,可以进一步减少循环索引和循环指针的加法操作。手动处理的话,需要知道余数大小,然后跳转到相应的位置进行处理。这里可以使用类似二分查找思想:条件跳转指令有
jl, je 和 jg,可以确定 2 个区间和
1 个值。
知道余数大小后,类似 C 语言中 switch 选择语句依次处理剩余部分:
1 | switch (Remainder) { |
10×1 循环展开+余数手动处理版本
1 | ncopy: |
该实现使用 ./benchmark.pl 测试, CPE = 8.02。
继续观察上述代码,还有 2 处可以优化:
- 每个 case 下,
mrmovq和rmmovq存在数据相关。 - 余数为 0 时,单独特判。假设每个余数等概率出现,那么很大概率这个条件跳转不会发生,从而增加了 CPE。所以,余数二分查找时要把 0 考虑进去。
针对 1 的优化,从 mrmovq 和 rmmovq
不会设置条件码入手,将这两条指令插入到
andq %r8, %r8 和 jle
之间,从而避免流水线暂停(这两条指令相邻时暂停一周期)。解决方法是:将前一个数的正负判断延迟到当前模块处理。具体实现为:
1 | Rn: |
该做法要求进入一个模块前,需要先加载一个数到寄存器 %r8 中。除了余数为 0 时,其他情形都需要 src[0],所以考虑加载 src[0] 到 %r8 中。
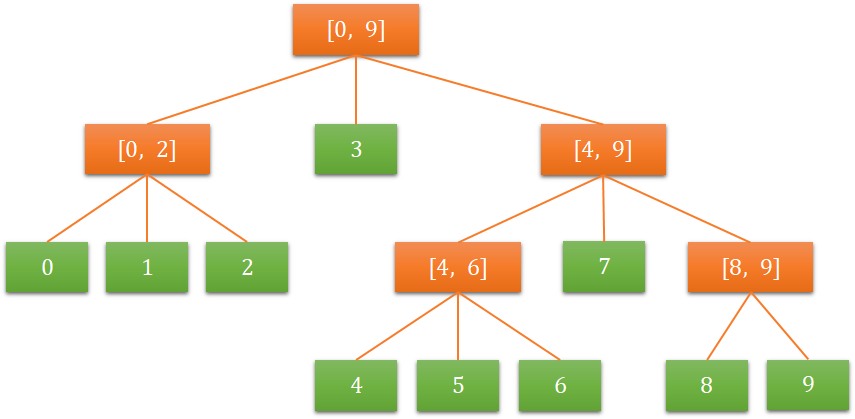
针对 2 的优化,要注意二分查找的分界点,该过程可通过动态规划来计算最少的指令数:
1 |
|
在区间为 [0, 9] 时,关键输出为:
1 | l = 7, r = 9, ret.first = 4, ret.second = 8 |
查找的关键点为:1,3,4,6,8。
在实现过程反复测试中,发现处理器更倾向于总是跳转,结合具体的查找实现,最终的关键点定位:1,3,5,7, 8。
优化后的版本:
1 | ncopy: |
注意,该版本去掉了 xorq %rax, %rax。
测试结果: