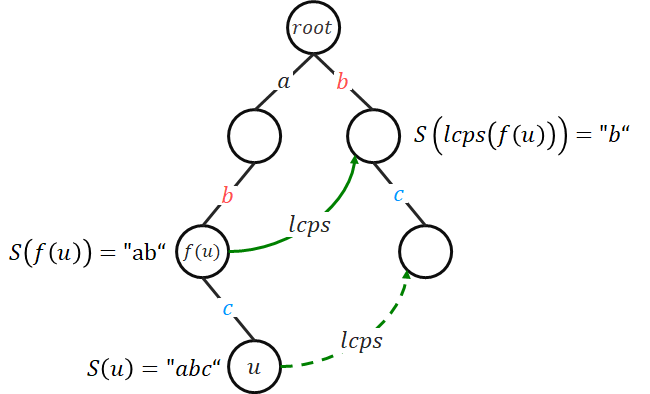
constint N = 5e5 + 7; // sum(|Wi|) constint E = 26; // character set size structAhoCorasick { int root = 0; int n, lcps[N], trans[N][E]; int end[N]; // end[u] > 0 : S(u) = Wi intnew_node(){ memset(trans[n], 0, E * sizeof(int)); lcps[n] = root, end[n] = 0; return n++; } voidinit(){ n = 0; root = new_node(); } voidinsert(constchar *str, int len){ int u = root; for (int i = 0; i < len; ++i) { int c = str[i] - 'a'; if (!trans[u][c]) trans[u][c] = new_node(); u = trans[u][c]; } ++end[u]; } voidLCPS(){ queue<int> Q({root}); while (!Q.empty()) { int u = Q.front(); Q.pop(); for (int c = 0; c < E; ++c) { if (trans[u][c]) { int v = lcps[u]; while (v != root && !trans[v][c]) v = lcps[v]; lcps[trans[u][c]] = u == root ? root : trans[v][c]; Q.push(trans[u][c]); } else trans[u][c] = trans[lcps[u]][c]; } } } };