KMP 算法解决在文本串(text)快速找出单词(word)的所有出现位置。
暴力匹配的时间复杂度为 ,而 KMP
算法通过引入最长前后缀,将检索的时间复杂度降至线性。
最长前后缀
lps indicates longest proper prefix which is also suffix.
最长前后缀(LPS, Longest proper Prefix and
Suffix)表示既是原串
的真前缀也是后缀的最长子串 ,其中
。
检索过程
假设已知单词串的每个前缀 的最长前后缀长度 ,且已经匹配 。继续匹配有两种情形:
- ,则匹配长度
+1。
- ,此时显然要重新找单词串的一个最长前缀
,使得 且 ,继续与 结尾的文本串匹配。
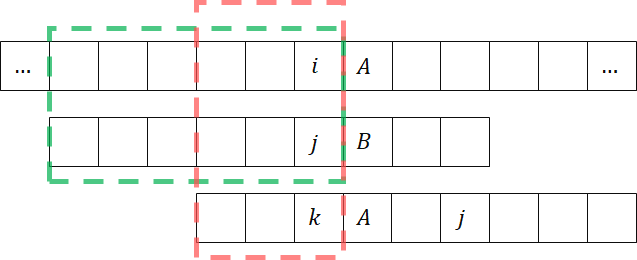 情形 2 示意图
图 1. 情形 2 示意图。虚线框表示相同部分。
情形 2 示意图
图 1. 情形 2 示意图。虚线框表示相同部分。
此时 与 的后缀相同,同时其本身是前缀。
令 ,若 ,则继续匹配。否则将 视为新的 ,则转化成情形 2 相同的子问题。
时间复杂度:匹配成功的复杂度是线性的。而匹配失败时会减小单词串的前缀长度,减一长度至少对应一次的成功匹配,此时时间复杂度也是线性的。故算法总的时间复杂度是线性的。
预处理
对于单词串的最长前后缀 ,本质上是单词串的自我匹配,即此时文本串为单词串。对应于检索过程中的两种情形,可以很容易地完成
的构造。
参考代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
lps[0] = -1;
for (int i = 1, j = -1; i < m; ++i) {
while (j >= 0 && W[i] != W[j + 1])
j = lps[j];
j += W[i] == W[j + 1];
lps[i] = j;
}
for (int i = 0, j = -1; i < n; ++i) {
while (j >= 0 && T[i] != W[j + 1])
j = lps[j];
j += T[i] == W[j + 1];
if (j == m - 1) {
j = lps[j];
}
}
|
