
简介
该论文作者取得了 2017 VQA Challenge 的第一,总结一些 tips 和 tricks
来提升 VQA 的表现。
这篇论文的每个实验使用不同的随机种子重复3次实验来统计结果。

一些细节
- 所有问题的长度固定 14。
- 问题特征
与图像特征 的融合使用 Hadamard product(逐项相乘)。 - 目标函数(损失函数)
- 作者使用了额外的数据集 Visual Genome(VG),共 485,000。 ## 关键点
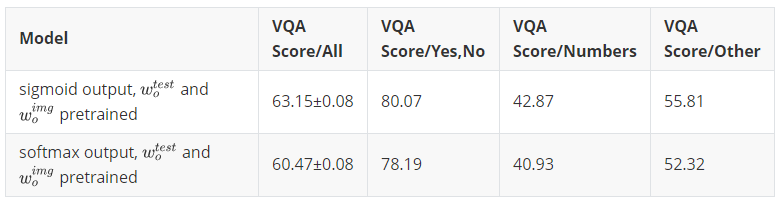
Sigmoid output
输出使用 sigmoid 将每个类别(或答案)归一化。
softmax 也可以用来归一化,但是会变成单个类别输出,而 sigmoid 可以输出多个类。这样可以适应一个问题有多个答案的情况。
 ### Soft scores as ground truth
targets
### Soft scores as ground truth
targetsVQA 中问题答案附有置信度,将答案向量化有 2 种做法:1)使用固定阈值将答案二值化;2)使用 sigmoid 或 softmax 来归一化答案。
做法1)就是 hard scores,每个类只有 0、1 两个选项。做法2)就是 soft scores,每个类都有一个浮点数的得分。
作者使用了两个简单的二值化进行对比
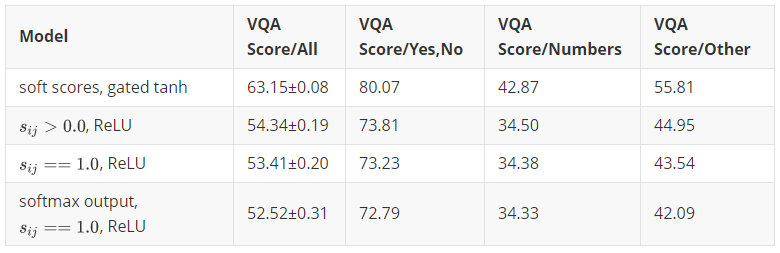 ### Gated tanh
activations
### Gated tanh
activations使用 gated tanh activations 作为激活函数,而不是常用的 Rectified Linear Unit(ReLU)。
激活函数
为训练参数, 表示 Hadamard product(逐项相乘)。 该激活函数之前被用于自然语言处理。 ### Bottom up attention
使用 bottom up attention 来提取图像特征,而不是直接使用 CNN 的特征层(feature map)。
Bottom up attention 基于 Faster R-CNN 框架,提取若干 Region of Interest(RoI)的特征,继而通过非线性层做 attention。论文里使用阈值来筛选出
个 RoI 并设置了 100 的上限(作者将数量 固定为 36,表现会差一些,但是减少了计算开销)。 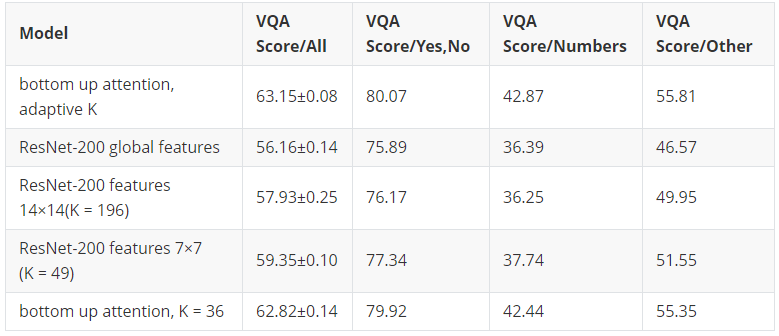
Attention 的非线性层
为问题表示向量, 为 RoI 的特征向量。 使用 bottom up attention 相对于传统的 CNN 提取特征,提升是很明显的。
Pretrained representations to initialize
论文提出了加入先验知识
和 来初始化输出层参数 使用 GloVe word embedding 初始化。 使用谷歌图片搜索 10 张对应图片并用 ResNet-10 提取特征,10 个特征向量均值化得到最终的向量表示。 这个做法提升了大约 0.87 个点。
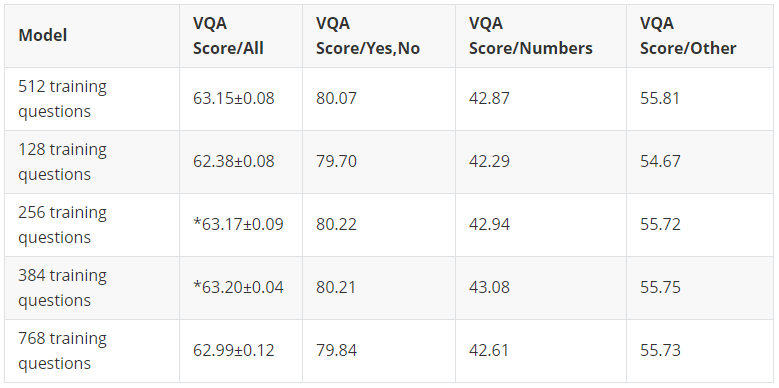
Larger mini-batches
通常来说,mini-batches 越大效果越好,但是大到一定程度后就不会有明显提升了,训练速度会慢。
Smart shuffling
- batch 通常从数据中随机抽取。针对 VQA 这个问题来说,同个问题关联到不同图像会得到不一样的答案(balanced pair),所以作者提出了 smart shuffling 控制 balanced pair 的比例。
- 这个做法 VQA 得分与随机做法差不多,但是提升了 Accuracy over paris。