
题目
Part A. Cache Simuator
要求
将 valgrind 存储跟踪作为输入,在 csim.c
中实现一个缓存模拟器,结果输出:命中,不命中和驱逐的数量(hit, miss,
eviction)。需要支持以下参数输入:
- -s:用于组索引的位数。
- -E:每组行数。
- -b:用于块的位数。
- -t:保存 valgrind 跟踪记录的文件。
Valgrind 输出格式为:
1 | I 0400d7d4,8 |
每行格式为 [space]operation address,size,L
表示加载数据,S 表示存储数据,M 表示修改数据(加载后存储)。指令 M
的存储必然命中,因此其结果只有两种:2 命中或 1 未命中 1 命中。
size 表示内存访问的字节数。测试数据保证内存访问不会出现跨越缓存块的边界,因此 size 在该实验中可忽略。
在该实验中只关注数据缓存,因此操作 I(表示指令加载)可忽略。
做法
因为只需要输出 (hit, miss, eviction) 三元组,所以实际实现过程中不必要完全复刻 cache 的过程。
对于参数 (s, E, b, t) 输入,使用 getopt 指令即可。
构造二维数组 cache[1 << s][E] 记录(标记,有效位)。因为组索引的位数 s 必然大于 0,所以有效位和标记位可以压入一个 64 位整数中。
在要驱逐缓存行时,使用 LRU 策略,因此还需要构造二维数组 last_used_time[1 << s][E] 记录每个缓存行上次使用时间。
1 |
|
Part B. Optimizing Matrix Transpose
要求
实现函数
void trans(int M, int N, int A[N][M], int B[M][N]) 转置矩阵
A 并存储到矩阵 B 中,限制:
- 缓存参数为:s = 5, E = 1, b = 5。
- 最多能够定义 12 个 int 类型的局部变量。
- 不允许修改矩阵 A,但能任意修改矩阵 B。
做法
b = 5 表示每个块缓存
s = 5 表示高速缓存中有
利用局部性原理,尝试 8×8 分块转置:
1 | void transpose_submit(int M, int N, int A[N][M], int B[M][N]) { |
使用 make && ./driver.py 测试:
1 | Cache Lab summary: |
在 32×32 和 61×67 效果还行,但是在 64×64 上 miss 很多。
使用以下指令查看具体的内存跟踪记录:
1 | ./test-trans -N 64 -M 64 |
可以看到,每次在加载(L)后的存储(S)指令就会 miss,并驱逐一条缓存。
当
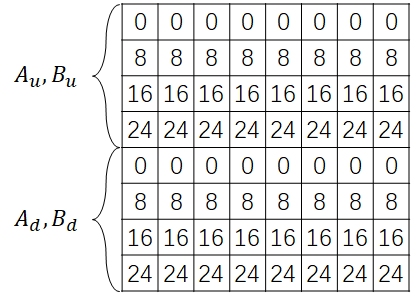
前 4 行定义为
读取
对于这种情况,可以开辟 8 个 int 的局部变量将
1 | void transpose_submit(int M, int N, int A[N][M], int B[M][N]) { |
使用 make && ./driver.py 测试:
1 | Cache Lab summary: |
64×64 的 miss 几乎不变,而 32×32 和 61×67 已满分。
目前为止,已经充分利用了 A 的空间局部性,然而对于 B 而言在 64×64 却非如此。
在读取
那么解决方法自然而然是先写 B 的前 4 行再写后 4 行。
1 | void transpose_submit(int M, int N, int A[N][M], int B[M][N]) { |
使用 make && ./driver.py 测试:
1 | Cache Lab summary: |
32×32 的 miss 略微提升,但是 64×64 的 miss 已显著下降(4613→1653)。
进一步的优化需要打印出 64×64 的组索引数值数组(这里本文假设了
1 | 00 00 00 00 00 00 00 00 01 01 01 01 01 01 01 01 02 ... |
观察可以得出以下结论:
- 当 8×8 块的左上角坐标不在对角线上时,
的组索引和 的组索引没有交集。 - 当 8×8 块的左上角坐标在对角线上时,此时冲突最为严重。
针对观察 1 的结论:在读完 A 的前 4 列后,A 的最后 4 行已被缓存而不会被覆盖。然而,在上一实现中,处理后 4 列时又从前 4 行开始读 A,浪费了已缓存的后 4 行。
所以,这里对于处理 A 的后 4 列时,从后往前读 A 的行,充分利用缓存。过程转变如下图所示:
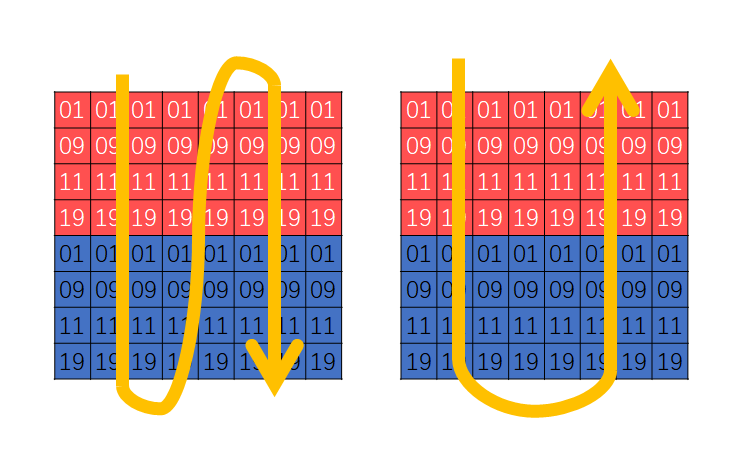
此外,由于每次只读 A 每行的 4 列,实际上用于缓存 A 的局部变量仅需 4 个。但这样的话会浪费上限为 12 的限制。因此,对于额外的 4 个局部变量可缓存 8×8 块第一行的后 4 列。这样充分利用了高速缓存的 8 个 int,从而在处理第一行的后 4 列时不用再从内存读取而避免了 miss 。
1 | void transpose_submit(int M, int N, int A[N][M], int B[M][N]) { |
使用 make && ./driver.py 测试:
1 | Cache Lab summary: |
剩余优化在于处于对角线的 8×8 分块,其冲突主要在于 A 的缓存组索引和 B 的缓存组索引相同。这里只需要针对这种情况构造一种冲突较少的方案即可。
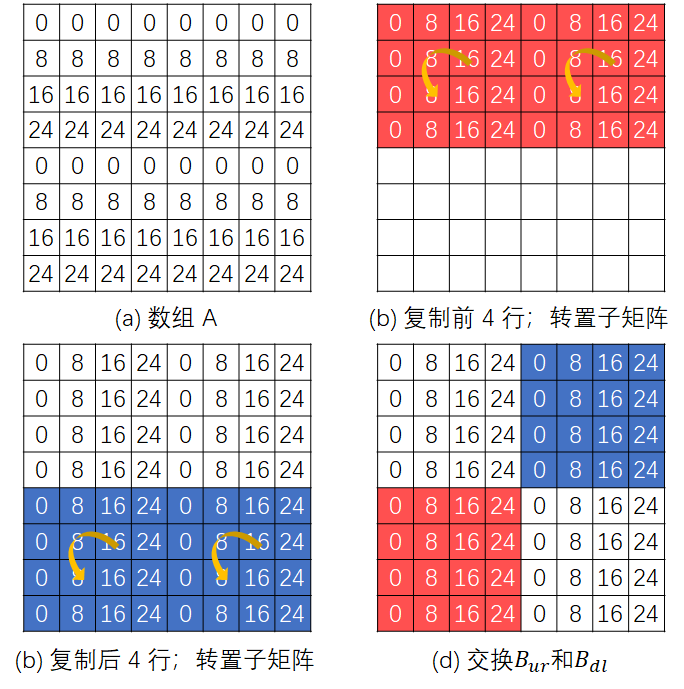
本文构造的方案为:
- 将 A 的前 4 行依次存储到 B 的前 4
行(不转置),此时缓存中均是
。转置 B 前 4 行的两个 4×4 子矩阵。由于缓存的存在,转置子矩阵不会导致任何的 miss。 - 同样处理后 4 行。注意,此时缓存的是
。 - 剩下的就是交换
的右子矩阵和 的左子矩阵,利用 8 个局部变量容易做到。
1 | void transpose_submit(int M, int N, int A[N][M], int B[M][N]) { |
使用 make && ./driver.py 测试:
1 | Cache Lab summary: |